Lição 5.9: Algoritmos de Junção — Como a Base de Dados Executa as Junções
Nas lições anteriores, escrevemos junções SQL concentrando-nos em que dados elas retornam. Mas como é que a base de dados executa realmente uma junção internamente? Compreender os algoritmos físicos que o motor utiliza é fundamental para escrever consultas com bom desempenho em grandes conjuntos de dados.
Os três principais algoritmos de junção são:
- Nested Loop Join (junção por ciclos aninhados)
- Hash Join (junção por hash)
- Merge Join (junção por fusão, também chamada Sort-Merge Join)
O planificador de consultas escolhe um automaticamente com base no tamanho das tabelas, nos índices disponíveis e na memória. Não podemos forçar um algoritmo específico em SQL padrão, mas compreender as trocas permite-nos escrever consultas e criar índices que orientam o planificador para a melhor escolha.
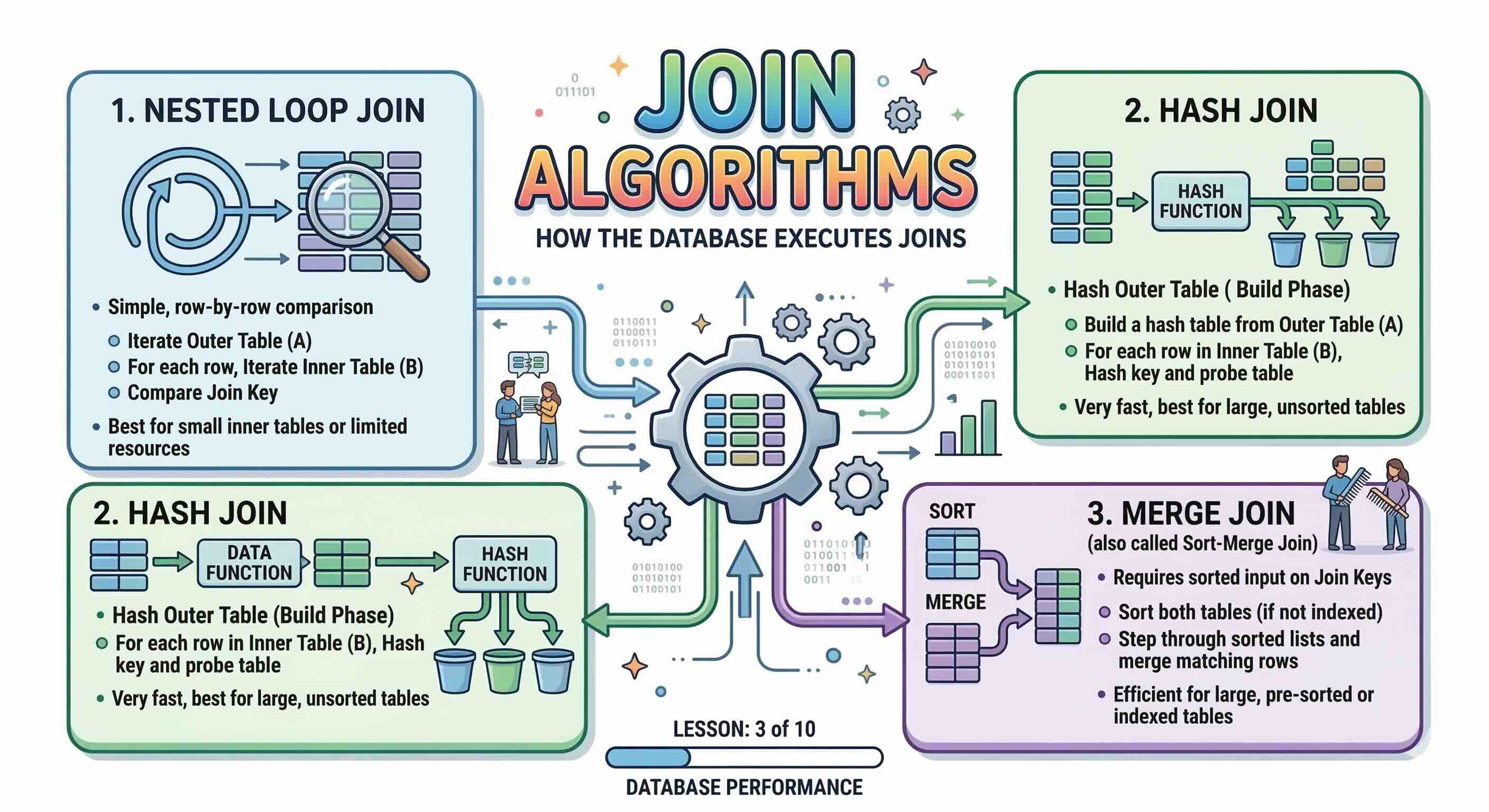
1. Nested Loop Join (junção por ciclos aninhados)
Como Funciona
O Nested Loop Join é o algoritmo mais simples. A base de dados escolhe uma tabela como tabela externa (condutora) e a outra como tabela interna. Em seguida, itera sobre cada linha da tabela externa e, para cada linha, pesquisa correspondências na tabela interna — essencialmente dois ciclos for aninhados.
Pseudo-código conceptual:
for each row R1 in outer_table:
for each row R2 in inner_table:
if R1.key = R2.key:
output(R1, R2)
Quando existe um índice na coluna de junção da tabela interna, a pesquisa interna torna-se uma procura rápida por índice em vez de um varrimento completo da tabela. Esta variante chama-se Index Nested Loop Join e é um dos caminhos de execução mais eficientes possíveis.
Quando o Planificador o Utiliza
- A tabela externa (condutora) é pequena.
- Existe um índice na coluna de junção da tabela interna.
- A junção usa uma condição de não-igualdade (
<,>,BETWEEN) — Hash Join e Merge Join requerem igualdade, por isso Nested Loop é a única opção neste caso.
Vantagens e Desvantagens
| Nested Loop Join | |
|---|---|
| Vantagens | Funciona com qualquer condição de junção, incluindo condições de intervalo |
| Extremamente rápido quando a tabela externa é pequena e a tabela interna está indexada | |
| Baixo consumo de memória — não precisa de construir estruturas de dados auxiliares | |
Começa a devolver os primeiros resultados imediatamente (ideal para consultas com LIMIT) | |
| Desvantagens | Muito lento em tabelas grandes sem índices — O(N × M) no pior caso |
| O desempenho degrada-se rapidamente à medida que ambas as tabelas crescem |
2. Hash Join (junção por hash)
Como Funciona
Um Hash Join funciona em duas fases:
- Fase de construção (Build phase): A base de dados lê a tabela mais pequena e constrói uma tabela de hash em memória, com a chave sendo a coluna de junção.
- Fase de sondagem (Probe phase): A base de dados varre a tabela maior e, para cada linha, consulta a tabela de hash para encontrar correspondências.
Pseudo-código conceptual:
-- Fase de construção
hash_table = {}
for each row R1 in smaller_table:
hash_table[ hash(R1.key) ].append(R1)
-- Fase de sondagem
for each row R2 in larger_table:
for each match in hash_table[ hash(R2.key) ]:
if R2.key = match.key:
output(R2, match)
Isto dá uma complexidade geral de O(N + M) — linear em ambos os tamanhos de tabela — tornando-o muito mais escalável do que um Nested Loop Join sem índices.
Quando o Planificador o Utiliza
- Junção de duas tabelas grandes numa condição de igualdade.
- Não existem índices úteis na(s) coluna(s) de junção.
- Há memória suficiente disponível para conter a tabela de hash (
work_memno PostgreSQL).
Vantagens e Desvantagens
| Hash Join | |
|---|---|
| Vantagens | Muito eficiente para junções de tabelas grandes — O(N + M) |
| Não requer índices nas colunas de junção | |
| Lida bem com dados não ordenados e sem ordem | |
| Desvantagens | Requer uma condição de igualdade — não pode ser usado para junções por intervalo |
| Exigente em termos de memória: se a tabela de hash não couber na RAM, é despejada para disco (muito mais lento) | |
| Custo de arranque elevado — a tabela de hash tem de ser construída antes de devolver quaisquer resultados |
Nota: No PostgreSQL, pode controlar o orçamento de memória com a definição work_mem. Aumentá-la reduz a probabilidade de dispendiosos derrames para disco em grandes Hash Joins.
3. Merge Join (junção por fusão)
Como Funciona
Um Merge Join requer que ambas as tabelas de entrada estejam ordenadas na coluna de junção. Em seguida, funde os dois fluxos ordenados simultaneamente — muito semelhante ao passo final do algoritmo clássico Merge Sort — avançando um ponteiro em cada fluxo para encontrar correspondências.
Pseudo-código conceptual:
sort outer_table by key -- ignorado se um índice ordenado for utilizado
sort inner_table by key -- ignorado se um índice ordenado for utilizado
p1 = início de outer_table
p2 = início de inner_table
while não é o fim de nenhum dos fluxos:
if outer[p1].key = inner[p2].key:
retornar linhas correspondentes e avançar ambos os ponteiros
elif outer[p1].key < inner[p2].key:
avançar p1
else:
avançar p2
A optimização crítica: se a tabela pode ser varrida através de um índice ordenado, o passo de ordenação é gratuito e o Merge Join torna-se um dos algoritmos mais eficientes disponíveis.
Quando o Planificador o Utiliza
- Ambas as tabelas são grandes e a condição de junção é igualdade.
- Ambas as tabelas já estão ordenadas, ou ambas podem ser varridas através de um índice ordenado.
- A consulta já requer
ORDER BYouGROUP BYna coluna de junção (a ordenação aconteceria de qualquer forma).
Vantagens e Desvantagens
| Merge Join | |
|---|---|
| Vantagens | Muito eficiente para tabelas grandes quando os dados estão pré-ordenados ou existe um índice ordenado |
Produz a saída em ordem ordenada, o que pode eliminar um passo ORDER BY posterior | |
| Consumo de memória estável e previsível | |
| Desvantagens | Requer apenas uma condição de igualdade |
| Passo de ordenação explícito dispendioso se nenhuma tabela estiver pré-ordenada e não estiver disponível nenhum índice | |
| Menos flexível que o Hash Join ao lidar com dados completamente não ordenados |
4. Escolher o Algoritmo Certo
O planificador de consultas escolhe o algoritmo automaticamente. Influencia a sua decisão indiretamente criando os índices certos e ajustando as configurações de memória.
| Cenário | Algoritmo provável |
|---|---|
| Tabela externa pequena + tabela interna indexada | Nested Loop Join |
| Duas tabelas grandes, igualdade, sem índices úteis | Hash Join |
| Duas tabelas grandes, igualdade, ambas ordenadas / indexadas em ordem | Merge Join |
Condição de não-igualdade (<, >, BETWEEN) | Nested Loop Join (única opção) |
Dicas práticas:
- Crie índices em colunas de chaves estrangeiras frequentemente utilizadas em junções — isto permite Index Nested Loop e Merge Joins rápidos.
- Se um Hash Join estiver a derramar para disco, considere aumentar
work_memou rever se a consulta pode ser reestruturada. - Use
EXPLAIN ANALYZEpara inspecionar qual algoritmo o planificador escolheu de facto e quanto tempo cada passo demorou:
EXPLAIN ANALYZE
SELECT a.first_name, a.last_name, f.title
FROM actor AS a
INNER JOIN film_actor AS fa ON a.actor_id = fa.actor_id
INNER JOIN film AS f ON fa.film_id = f.film_id;
Procure palavras-chave como Hash Join, Merge Join ou Nested Loop no plano de saída para identificar o algoritmo escolhido e o seu custo.
Principais Conclusões desta Lição
- Nested Loop Join itera linhas em ciclos aninhados — rápido para tabelas pequenas com índices de suporte, muito lento para tabelas grandes não indexadas; o único algoritmo que suporta condições de não-igualdade.
- Hash Join constrói uma tabela de hash em memória a partir da tabela mais pequena e sonda-a — eficiente para junções de tabelas grandes não indexadas por igualdade, mas exigente em memória.
- Merge Join lê dois fluxos pré-ordenados simultaneamente — ideal quando os dados já estão em ordem (ex. via um índice) e a junção é por igualdade; produz resultados em ordem ordenada como bónus.
- Os três algoritmos suportam junções por igualdade; apenas o Nested Loop suporta também condições de intervalo.
- Influencia a escolha do planificador através de índices, configurações de memória (
work_mem) e estrutura da consulta — não especificando o algoritmo em SQL. - Use sempre
EXPLAIN ANALYZEpara verificar qual algoritmo está realmente a ser utilizado e onde o tempo está a ser gasto.